
[数据结构 - 第6章] 树之二叉排序树(C语言实现)
一、什么是二叉排序树?
对于普通的顺序存储来说,插入、删除操作很简便,效率高;而这样的表由于无序造成查找的效率很低。
对于有序线性表来说(顺序存储的),查找可用折半、插值、斐波那契等查找算法实现,效率高;而因为要保持有序,在插入和删除时不得不耗费大量的时间。
那么,如何既使得插入和删除效率不错,又可以比较高效率地实现查找的算法呢?
先看一个例子:
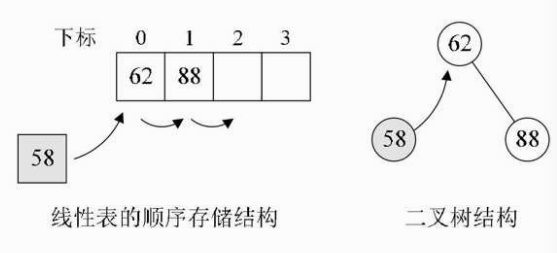
现在我们的目标是插入和查找同样高效。假设我们的数据集开始只有一个数 {62},然后现在需要将 88 插入数据集,于是数据集成了 {62,88},还保持着从小到大有序。再查找有没有 58,没有则插入,可此时要想在线性表的顺序存储中有序,就得移动 62 和 88 的位置,如下左图,可不可以不移动呢?嗯,当然是可以,那就是二叉树结构。当我们用二叉树的方式时,首先我们将第一个数 62 定为根结点,88 因为比 62 大,因此让它做 62 的右子树,58 因比 62 小,所以成为它的左子树。此时 58 的插入并没有影响到 62 与 88 的关系,如下右图所示。
也就是说,若我们现在需要对集合 {62,88,58,47,35,73,51,99,37,93} 做查找,在我们打算创建此集合时就考虑用二叉树结构,而且是排好序的二叉树来创建。如下图所示,62、88、58 创建好后,下一个数 47 因比 58 小,是它的左子树(见③),35 是 47 的左子树(见④),73 比 62 大,但却比 88 小,是 88 的左子树(见⑤),51 比 62 小、比 58 小、比 47 大,是 47 的右子树(见⑥),99 比 62、88 都大,是 88 的右子树(见⑦),37 比 62、58、47 都小,但却比 35 大,是 35 的右子树(见⑧),93 则因比 62、88 大是 99 的左子树(见⑨)。
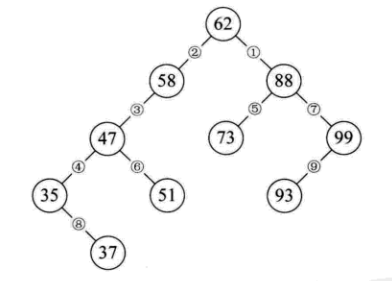
这样我们就得到了一棵二叉树,并且当我们对它进行中序遍历时,就可以得到一个有序的序列 {35,37,47,51,58,62,73,88,93,99},所以我们通常称它为二叉排序树。
二叉排序树(Binary Sort Tree),又称为二叉查找树。它或者是一棵空树,或者是具有下列性质的二叉树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉排序树。
构造一棵二叉排序树的目的,其实并不是为了排序,而是为了提高查找和插入删除关键字的速度。不管怎么说,在一个有序数据集上的查找,速度总是要快于无序的数据集的,而二叉排序树这种非线性的结构,也有利于插入和删除的实现。
二、基本操作
首先提供一个二叉树的结构:
/* 二叉树的链表结点结构定义 */
typedef struct BiTNode /* 结点结构 */
{
int data; // 结点数据
struct BiTNode *lchild, *rchild; // 左右孩子指针
} BiTNode, BiTree;
2.1 二叉排序树查找操作
思路:当二叉树非空时,首先将待查找的键值与根节点的键值比较,若小于根节点的键值,则继续查找左子树,否则查找右子树。重复上述过程,直至查找成功返回 TRUE,否则返回 FALSE。
// 递归查找二叉排序树T中是否存在key,指针f指向T的双亲,其初始调用值为NULL
Status searchBST(BiTree *T, int key, BiTree *f, BiTree **p)
{
if (T == NULL) // 查找不成功,指针p指向查找路径上访问的最后一个结点并返回FALSE
{
*p = f;
return FALSE;
}
else if (T->data == key) // 查找成功,则指针p指向该数据元素结点,并返回TRUE
{
*p = T;
return TRUE;
}
if (key < T->data)
return searchBST(T->lchild, key, T, p); // 在左子树中继续查找(注意此时f的赋值)
else
return searchBST(T->rchild, key, T, p); // 在右子树中继续查找
}
2.2 二叉排序树插入操作
思路:与查找类似,但需要一个父节点来进行赋值。代码如下:
// 当二叉排序树T中不存在关键字等于key的数据元素时,插入key并返回TRUE,否则返回FALSE
Status insertBST(BiTree **T, int key)
{
BiTree *p; // 指针p指向查找路径上访问的最后一个结点
// 不存在关键字等于key的数据元素时,才插入
if (!searchBST(*T, key, NULL, &p)) // 通过指针p获得查找路径上访问的最后一个结点的地址
{
BiTNode *temp = (BiTNode *)malloc(sizeof(BiTNode));
temp->data = key;
temp->lchild = temp->rchild = NULL;
// 根据key与最后一个节点key值比较大小,决定是在左子树还是右子树插入
if (p == NULL)
*T = temp; // T为空树,则插入temp为新的根结点
else if (key < p->data)
p->lchild = temp;
else
p->rchild = temp;
return TRUE;
}
else
return FALSE; // 树中已有关键字相同的结点,不再插入
}
2.3 二叉排序树删除元素操作
对于二叉排序树的删除要注意,我们不能因为删除了结点,而让这棵树变得不满足二叉排序树的特性,所以删除需要考虑多种情况。
(1)删除叶子结点
直接删除,不影响原树,如下图所示:
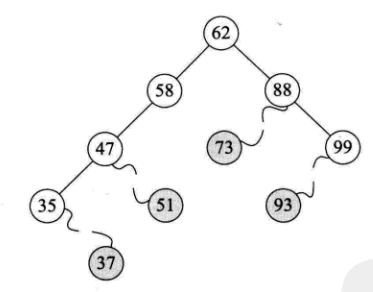
(2)删除仅有左或右子树的结点
节点删除后,将它的左子树或右子树整个移动到删除节点的位置就可以,子承父业,如下图所示:
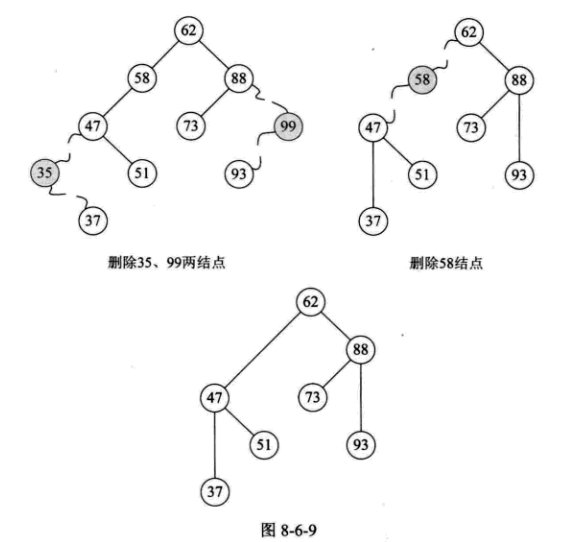
(3)删除左右子树都有的结点
我们仔细观察一下,47 的两个子树中能否找出一个结点可以代替 47 呢?果然有,37 或者 48 都可以代替 47,此时在删除 47后,整个二叉排序树并没有发生什么本质的改变。
为什么是 37 和 48?对的,它们正好是二叉排序树中比它小或比它大的最接近 47 的两个数。也就是说,如果我们对这棵二叉排序树进行中序遍历,得到的序列 {29, 35, 36, 37, 47, 48, 49, 50, 51, 56, 58, 62, 73, 88, 93, 99}。
因此,比较好的办法就是,找到删除结点 p 的中序序列的直接前驱(或直接后驱)s,用 s 来替换结点 p,然后删除结点 s,如下图所示:
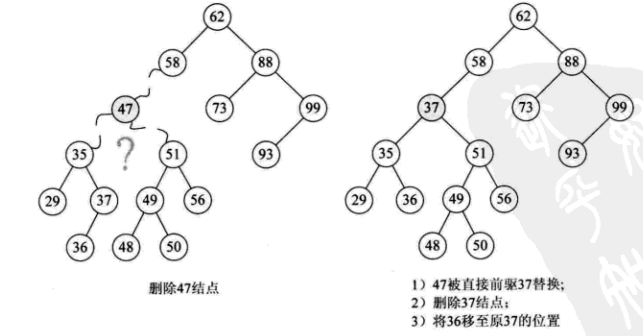
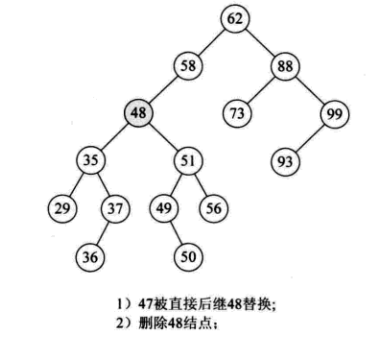
根据我们对删除结点三种情况的分析:
- 叶子结点;
- 仅有左或右子树的结点;
- 左右子树都有的结点。
下面是 deleteNode 的代码:
// 从二叉排序树中删除结点p,并重接它的左或右子树。
Status deleteNode(BiTree **p)
{
BiTree *q, *temp;
if ((*p)->rchild == NULL) // 右子树空则只需重接它的左子树(待删结点是叶子也走此分支)
{
q = *p; *p = (*p)->lchild; free(q);
}
else if ((*p)->lchild == NULL) // 只需重接它的右子树
{
q = *p; *p = (*p)->rchild; free(q);
}
else /* 左右子树均不空 */
{
q = *p;
temp = (*p)->lchild;
while (temp->rchild) // 转左,然后向右到尽头(找待删结点的前驱)
{
q = temp;
temp = temp->rchild;
}
(*p)->data = temp->data; // temp指向被删结点的直接前驱(将被删结点前驱的值取代被删结点的值)
if (q != *p)
q->rchild = temp->lchild; // 重接q的右子树
else
q->lchild = temp->lchild; // 重接q的左子树
free(temp);
}
return TRUE;
}
2.4 二叉排序树删除结点操作
下面这个算法是递归方式对二叉排序树 T 查找 key,查找到时删除。
// 若二叉排序树T中存在关键字等于key的数据元素时,则删除该数据元素结点
Status deleteBST(BiTree **T, int key)
{
if (!*T) // 不存在关键字等于key的数据元素
return FALSE;
else
{
if (key == (*T)->data) // 找到关键字等于key的数据元素
return deleteNode(T);
else if (key < (*T)->data)
return deleteBST(&(*T)->lchild, key);
else
return deleteBST(&(*T)->rchild, key);
}
}
可以看出,这段代码和前面的二叉排序树查找几乎完全相同,唯一区别在于当找到对应 key 值的结点时,执行的是删除操作。
三、主函数执行
int main(void)
{
int a[10] = { 62, 88, 58, 47, 35, 73, 51, 99, 37, 93 };
BiTree *T = NULL;
// 插入元素
for (int i = 0; i<10; i++)
{
insertBST(&T, a[i]);
}
// 删除元素
deleteBST(&T, 93);
deleteBST(&T, 47);
// 中序递归遍历
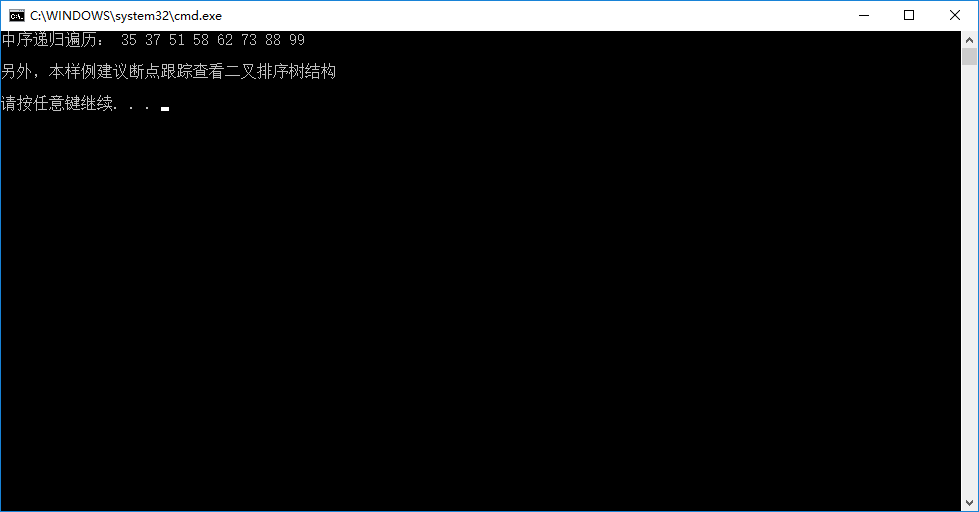
printf("中序递归遍历: ");
inOrderTraverse(T); // 中序递归遍历,会得到一个有序的序列
printf("\n\n另外,本样例建议断点跟踪查看二叉排序树结构\n\n");
return 0;
}
输出结果如下图所示:
四、二叉排序树总结
总之,二叉排序树是以链接的方式存储,保持了链接存储结构在执行插入或删除操作时不用移动元素的优点,只要找到合适的插入和删除位置后,仅需修改链接指针即可。
而对于二叉排序树的查找,走的就是从根结点到要查找的结点的路径,其比较次数等于给定值的结点在二叉排序树的层数。技术情况,最少为1次,即根结点就是要找的结点;最多也不会超过树的深度。也就是说,二叉排序树的查找性能取决于二叉排序树的形状。可问题是,二叉排序树的形状是不确定的。
例如 {62, 88, 58, 47, 35, 73, 51, 99, 37, 93} 这样的数组,我们可以构建如下左图的二叉排序树。但如果数组元素的次序是从小到大有序,如 {35, 37, 47, 51, 58, 62, 73, 88, 93, 99},则二叉排序树就成了极端的右斜树,注意它依然是一棵二叉排序树,如下右图。此时,同样是查找结点 99,左图只需要两次比较,而右图就需要 10 次比较才可以得到结果,二者差异很大。
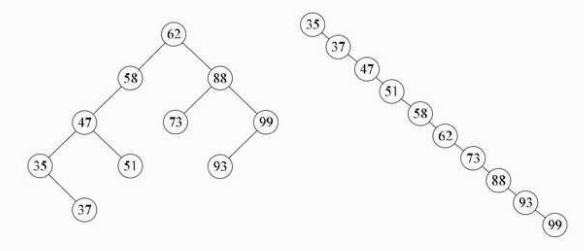
也就是说,我们希望二叉排序树是比较平衡的,即其深度与完全二叉树相同,那么查找的时间复杂也就为 O(logn),近似于折半查找。而像上图右边这种情况,查找时间复杂度为 O(n),这等同于顺序查找。因此,如果我们希望对一个集合按二叉排序树查找,最好是把它构建成一棵平衡的二叉排序树。
参考:
《大话数据结构 - 第8章》 查找

